Introduction
文本到音乐的检索任务是检索与自然语言最相关的音乐。为了在大型音乐数据平台中找到符合用户偏好的音乐,用户可能会采用自由格式的文本描述进行查询。先前的工作主要集中在学习embedding,将音乐和文本映射到同一个联合嵌入空间,从而简化文本到音乐的检索为跨模态最近邻检索。
在多样化的文本查询方面,当前方法致力于学习一个连接音乐和内容语义的联合嵌入空间,然而存在一些限制:
- 文本查询不仅涉及内容语义(流派、情绪和主题),还可能涉及metadata(如曲目、专辑和艺术家姓名)的查询(例如,“类似于Stevie Wonder的音乐”);
- 先前的研究将 metadata 文本纳入整体的训练过程;然而,他们并没有在评估中明确评估基于 metadata 的检索;
进一步使这一综合评估复杂化的是缺乏包含内容描述、metadata 和相对相似性知识的大规模音乐文本配对数据集。
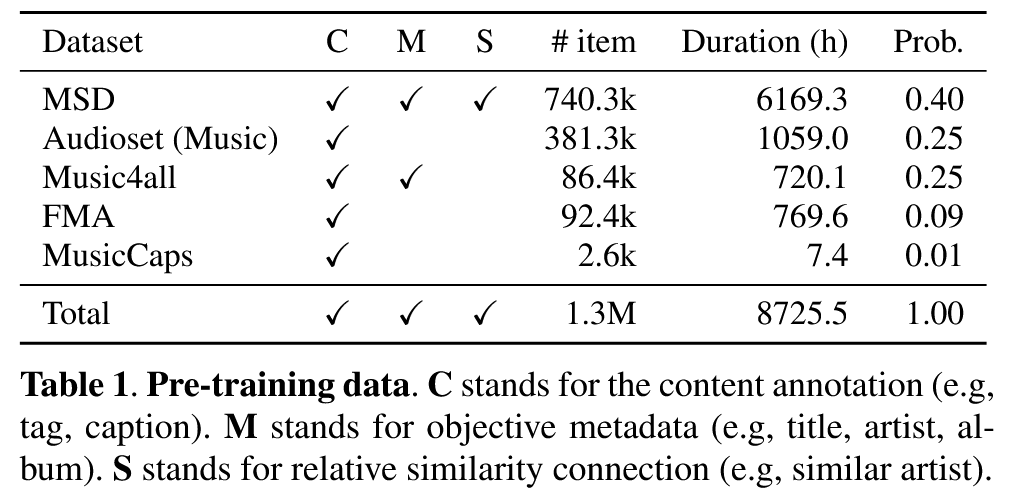
为了解决这个问题,本文收集了一个包含130万条记录的公共音乐 – 文本对数据集。
Method
文本 – 音乐检索
TTMR++学习配对的文本和音乐,并通过训练将这些配对数据映射到联合嵌入空间。这种映射旨在最大化表示音乐和文本的向量之间的相似性,如下图所示。
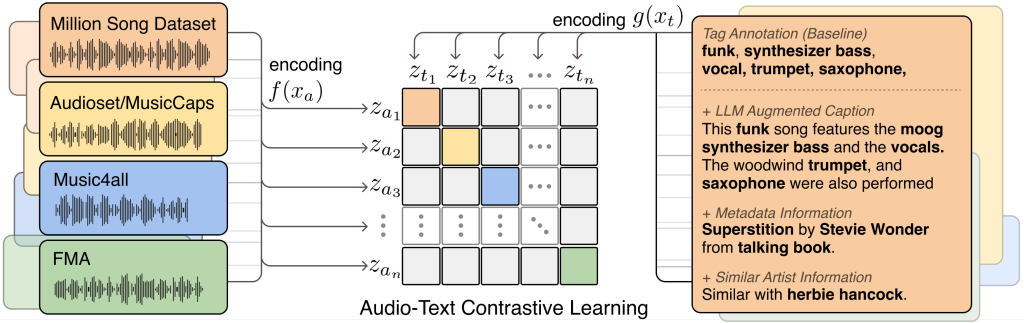
方法没有什么太多需要介绍的地方,InfoNCE Loss和编码器的介绍都是比较基础的内容。
丰富音乐描述
通过 Finetuned-LLaMA 的音乐描述
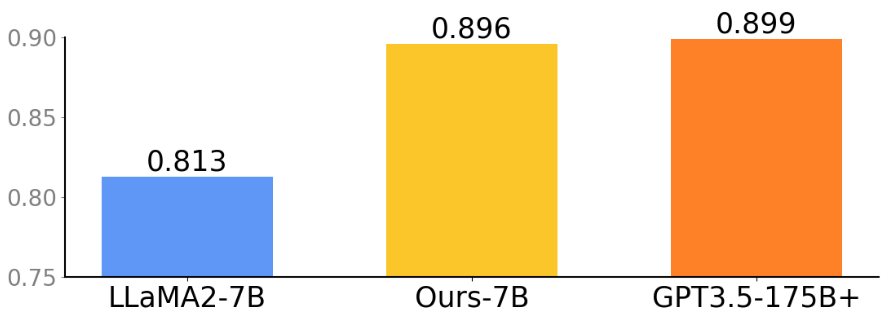
为了实现与 GPT-3.5 相当的性能,本文采用instruction fine-tuning策略,将LLaMA2-7B转化为一个指令跟随模型。由于 LP-MusicCaps 和 WavCaps 数据集是由GPT-3.5构造的数据集,然后使用PEFT【1】(尤其是LoRA)对LLaMA2-7B模型进行了微调。
本文使用 MusicCaps 评估 caption 生成模型,该数据集包括 tags 和 caption,这些作为评估的基准。通过将指令(任务描述)与tags(与音乐相关的标签)拼接起来,作为模型的输入来生成 pseudo-caption。在下图中,通过计算pseudo-caption与caption之间的 BERT score 来进行比较。在 tags 到 caption 的任务中,微调 LLaMA2-7B的表现与GPT3.5-175B相当。使用这个微调的LLaMA2为MSD、AudiosetMusic、Music4All和FMA生成伪标题(这些数据集缺乏标题注释)。
通过 metadata知识图谱的音乐描述
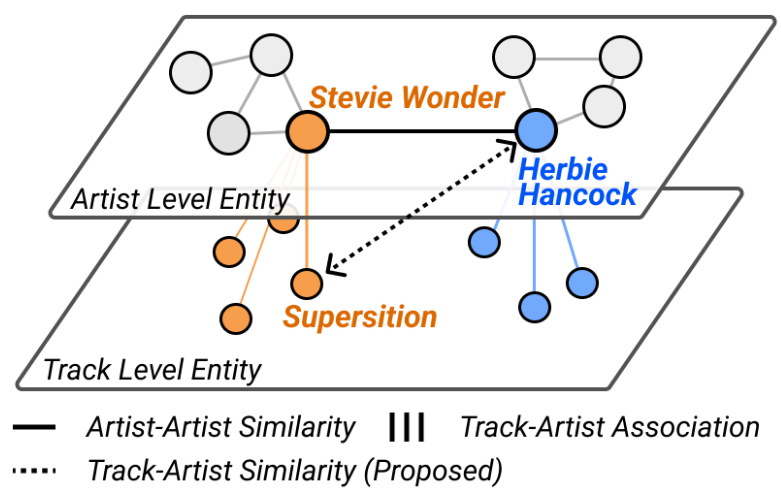
在 metadata 查询场景中,利用音乐知识图谱构建了音频的 metadata 描述。首先,利用客观 metadata 关联和模板(音乐曲目 {title} 由 {artist} 来自 {album}),为标题、艺术家和专辑名称创建文本描述,并与相应的音频配对。其次,提出了音频-艺术家相似度的概念,通过连接艺术家相似度关系和 metadata 实现关联。例如,当我们有信息表明Stevie Wonder和Herbie Hancock之间的相似性时,我们将艺术家相似度继承到Stevie Wonder的音频Superstition上,形成与Herbie Hancock的音频-艺术家相似度。音轨-艺术家相似度被合成到一个文本样本中(与艺术家 {artist} 类似)。本文利用OLGA训练集中的14k艺术家,为552k MSD音频建立了总共890万条音频-艺术家相似度连接。在每个训练步骤中,随机采样一个相似的艺术家,并将其与音频关联,从而训练模型。
统一联合训练框架
采用了一种联合训练方法,利用了多个数据集。允许单一的模型同时理解共享词汇语义,并捕捉音频和各种形式的自然语言语义(即内容、metadata和相对相似性)之间的关系。在一个批次中包含不同的数据集,可以使音频样本与更多样化的负文本一起进行训练。同时,文本数据可以从更广泛的音频录音质量和音色中学习。为了减轻低资源数据集的限制,本文采用了显式采样比例【2】。
总结
论文整体大概就是这些内容,后续的实验部分也没有什么创新点,大概就是讲自己的检索效果很不错,然后这篇工作最大的收获就是数据集的获取,非常不错,之前用这个训了一个模型,效果还是好的。这种对原本数据集进行加工丰富的工作一定是对的,工作有意义,可以很大程度上提高当前数据集的进步。
【1】PEFT(Parameter-Efficient Fine-Tuning) 是一种在微调大型预训练模型时,通过减少需要更新的参数数量来提高计算效率的技术。PEFT的核心思想是在微调过程中,不必修改或更新所有的参数,而是只修改一小部分参数,这样可以大大减少计算资源的消耗,并提高微调效率。PEFT 方法特别适用于大规模的预训练语言模型(如 GPT、BERT 等),因为这些模型通常有非常多的参数,而对所有参数进行微调会消耗大量的计算资源和存储空间。
PEFT的常见实现方法
- LoRA(Low-Rank Adaptation):LoRA 通过在模型的每一层引入低秩矩阵来进行微调。在LoRA中,原始模型的权重被冻结,低秩矩阵(通常维度较小)是唯一需要更新的参数。这种方法显著降低了微调的计算开销,同时保持了预训练模型的性能。
- Adapters:Adapters 通过在预训练模型的每一层插入一个小型神经网络模块,来适应新的任务。在微调过程中,只有这些适配器的参数会被更新,原始模型的权重保持不变。适配器方法特别适合多任务学习,因为不同任务可以共享适配器模块。
- BitFiT:BitFit 通过更新模型的偏置项(bias terms)来进行微调,而不修改其他参数。这个方法对于资源非常有限的情况非常有用,计算开销极小。
- Prompt-Tuning:Prompt-Tuning 是一种通过优化输入 prompt 来微调预训练模型的策略,而不是修改模型的权重。在这种方法中,我们可以通过修改输入的提示内容来使模型在特定任务上表现更好,而无需调整模型的内部参数。
【2】低资源数据集指的是相对较小或数据较少的某些数据集。由于数据量有限,直接使用这些数据进行训练可能会导致模型表现不佳,因为模型可能更倾向于学习训练集中的大规模数据,而忽略低资源数据集中的样本。为了解决这个问题,作者采用了显式采样比例策略,通过在训练过程中人为地调整不同数据集的采样比例,确保 低资源数据集 的样本能够在训练中得到足够的训练机会。这样,低资源数据集中的样本不会因为数量少而在训练过程中被“忽视”,从而改善模型对这些数据的学习能力。假设你有两个数据集:数据集A,包含大量数据。数据集B(低资源数据集),包含的样本较少。在训练时,你可能会按照比例(例如,1:4)选择数据集B的样本,即使它的数据量较少。这就意味着在每个训练步骤中,你会从数据集A和数据集B中按比例选择样本进行训练,而不是仅仅使用数据集A。这种策略帮助确保模型能够同时学习到数据集B的特性,而不会过度依赖数据集A。
