0 图片分类问题
图片分类问题就是辨认输入的图片类别的问题,且图片的类别属于事先给定的一个类别组中。尽管这看起来很简单,但这是计算机视觉的一个核心问题,且有很广泛的实际应用。并且,有很多的计算机视觉的问题最终会化简为图片分类问题。
举例来说,假设有一个图片分类模型,它对于输入的三通道的图片会预测其属于四个标签(label)的概率(四个标签为 cat, dog,hat,mug)。下图所示的图片是一张248像素宽度,400像素高度的图片,并且有RGB三通道,那么这张图片可以用 3*248*400 个数字表示,每个数字范围从 0到255,模型的任务就是接受这些数字,然后预测出这些数字代表的标签(label)。

1 数据驱动方法
1.1 当前的挑战
虽然图片识别对于人来说是一件轻松的事情,但是对于计算机来说,由于接受的是一串数字,对于同一个物体,表示这个物体的数字可能会有很大的不同,所以使用算法来实现这一任务还是有很多挑战的,具体来说:
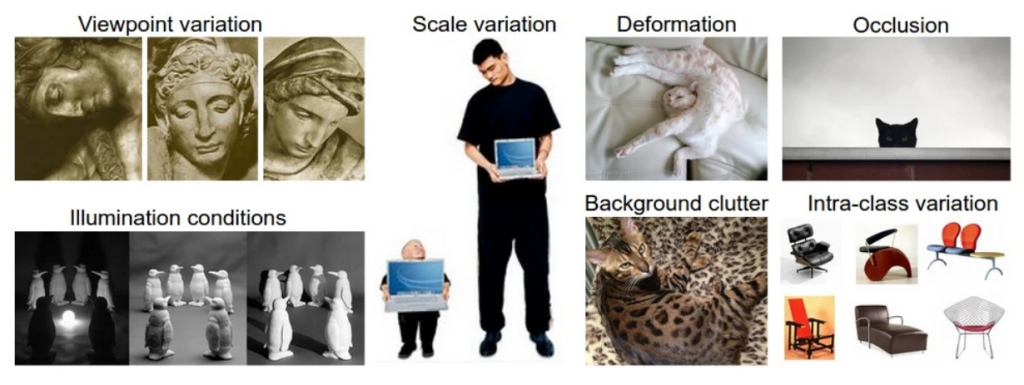
- 观察角度的变化 Viewpoint variation:一句诗可以很好概括,“不识庐山真面目,只缘身在此山中”。
- 尺度变换 Scale variation:图片大小比例的变化也会使得数据发生改变。
- 变形 Deformation:很多物体的外形不是一成不变的,比如众所周知,猫是液体。
- 遮挡 Occlusion:要被识别的物体可能被遮挡,只露出一部分。
- 光线条件 Illumination conditions:环境光线的变化对物体的图片也会有很大的影响。
- 背景干扰 Background clutter:如果物体和背景有很相似的颜色和纹路,那么就很难被识别。
- 物种变异 Intra-class variation:同一物种可能也有差异很大的形态。
1.2 数据驱动方法
那么我们如何设计算法去分辨不同的类别呢?我们不会去设计一个特定的算法来解决这样的问题,而是将大量带有标签的数据送给一个模型,让模型自己学习,这种方式就成为数据驱动方法,因为它依赖于一个带有标签的数据集合。
所以通常图片识别任务的流水线如下:
- 输入:输入 N 张图片,图片的总类别数量为 K,我们称这一部分的数据为训练集。
- 学习:使用模型在训练集中学习,提取每一个种类的特征。我们称之为 训练一个模型或者训练一个分类器。
- 评估:在最后,我们需要评估这个训练的模型好坏。这时需要一个之前从来都没使用过的新数据集(保证类别也在 K 类之中),然后在新的数据集上预测每张图片的种类,我们期望的是分类正确的图片越多越好。
2. 最近邻域分类器 NN
2.1 数据集和原理
首先我们来介绍一下最近邻域分类器,这是一个十分简单并且不常用于分类的算法,但是通过这个算法, 我们也可以大致了解解决图片分类问题的大致方法。本次使用的数据集是MNIST(手写数字识别) 和
CIFAR-10(这是一个有名的公开图片数据集,由60000张 的图片组成,一共有10个种类,一般我们将其中的50000张作为训练集,10000张作为测试集,下图左就是10个类别的部分图片。)

现在我们的训练集中就有了50000张图片,每个类别5000张,对于测试集10000张图片中的每一张图片,我们要做的是将其与训练集中的每一张图片进行比较,然后将这种图片与训练集中最相似的图片归为一类,上图右就是部分分类后的结果,可以发现,存在很多的误分类,原因在于虽然图片的种类不同,但是两种图片的颜色图案等非常类似,就容易被归为一类。
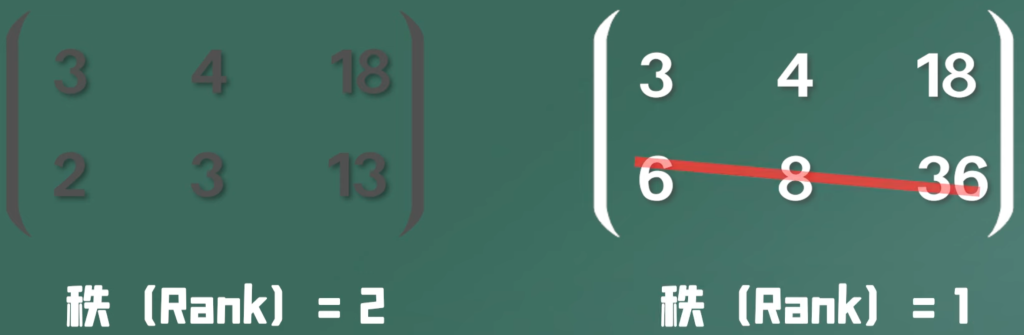
那么在最近邻域算法中,我们衡量两张图片是否相近的标准是什么呢?一种最简单的标准就是 L1距离,假设我们将两张图片分别表示为两个向量 I1、I2,那么L1距离的定义如下:
$$L1(I1, I2)=\sum_p|I1-I2|$$
一个简单的计算流程演示:
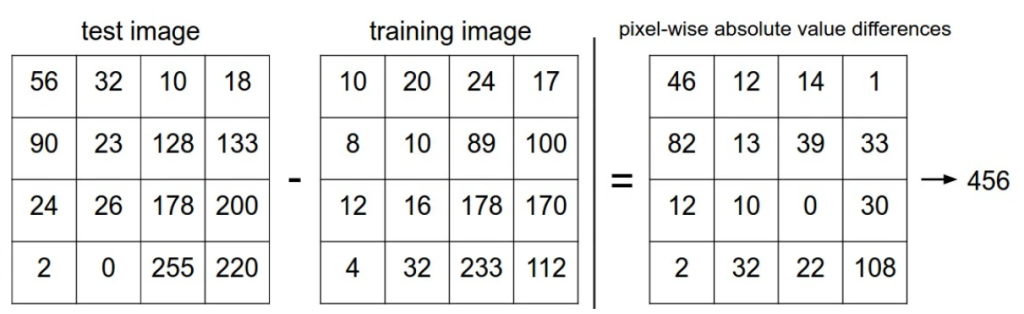
对于两种图片的衡量标准还有 L2 距离,定义如下:
$$L2(I1, I2)=\sum_p(I1-I2)^2$$
2.2 代码实现
课程一内容
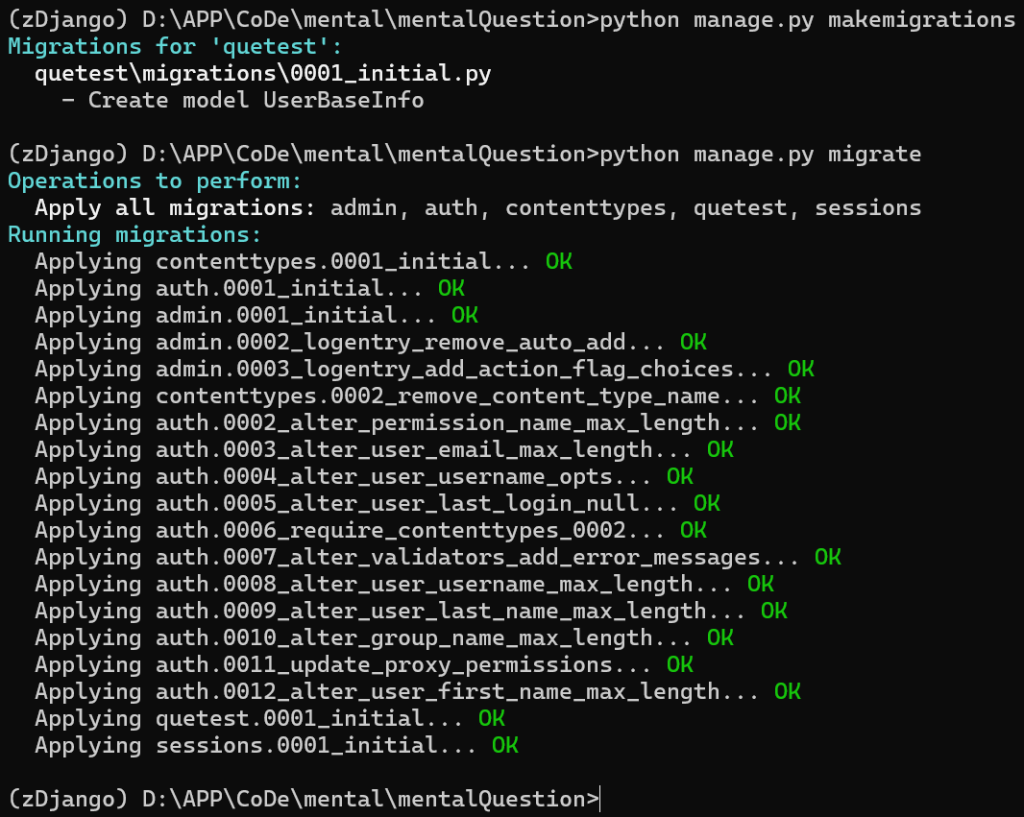
安装虚拟环境:
pip install numpy matplotlib torchvision导入目标处理的库
import os
import numpy as np
import matplotlib.pyplot as plt
from torchvision.datasets import MNIST首先我们需要处理 MNIST 数据集,利用torchvision下载数据集。
data_path = r'C:\code\ccs2\check\data'
def downloaddataset():
# 下载数据集
train_dataset_no = MNIST(data_path, train=True, download=True)
test_dataset_no = MNIST(data_path, train=False, download=True)
downloaddataset()将其以四个数组的形式表示,分别为 训练集数据、训练集标签、测试集数据、测试集标签,下面的代码中 Xtr 表示训练集数据,Ytr 表示训练集标签,得到数据后将其拉成一条向量,便于计算。
def load_mnist(root=data_path, download=False):
"""
读 MNIST 手写数字。
返回四个东西:
Xtr: 训练图片,形状(训练数量, 28, 28)
Ytr: 训练标签,形状(训练数量,)
Xte: 测试图片,形状(测试数量, 28, 28)
Yte: 测试标签,形状(测试数量,)
"""
# 1) 读取数据集(如果本地没有且 download=True,就会自动下载)
train_set = MNIST(root=root, train=True, download=download) # 6万张
test_set = MNIST(root=root, train=False, download=download) # 1万张
# 2) 把训练集里的图片和标签一个一个取出来,装进列表
train_images = [] # 存图片
train_labels = [] # 存标签
for img, lbl in train_set:
# img 是一张 28x28 的灰度图(PIL 图片),先把它变成 numpy 数组
img_array = np.array(img, dtype=np.uint8)
# print(img_array.shape)
train_images.append(img_array)
train_labels.append(int(lbl))
# 3) 同样的方法处理测试集
test_images = []
test_labels = []
for img, lbl in test_set:
img_array = np.array(img, dtype=np.uint8)
test_images.append(img_array)
test_labels.append(int(lbl))
# 4) 把列表转成 numpy 数组,方便后面计算
Xtr = np.array(train_images) # (60000, 28, 28)
Ytr = np.array(train_labels) # (60000,)
Xte = np.array(test_images) # (10000, 28, 28)
Yte = np.array(test_labels) # (10000,)
return Xtr, Ytr, Xte, Yte
# ---------- 主流程 ----------
Xtr, Ytr, Xte, Yte = load_mnist(download=False) # 若本地没数据,可改为 True课程二内容
可视化一张图片
# 可选:查看一张训练图片
SAMPLE_INDEX = 0
img = Xtr[SAMPLE_INDEX]
label = Ytr[SAMPLE_INDEX]
print("Label:", label)
plt.imshow(img, cmap='gray')
plt.title(f"Label = {label}")
plt.axis('off')
plt.show()
plt.imsave('mnist_sample.png', img, cmap='gray')
print("图片已通过 matplotlib 保存为 mnist_sample.png")
模型构建过程
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X, k=1):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
# 找到距离最小的 k 个训练样本
knn_indices = np.argsort(distances)[:k]
knn_labels = self.ytr[knn_indices]
# 多数投票(k=1 时等价于原始版本)
Ypred[i] = np.bincount(knn_labels).argmax()
return Ypred课程三内容
整体pipline搭建
# ---------- 主流程 ----------
Xtr, Ytr, Xte, Yte = load_mnist(download=False) # 若本地没数据,可改为 True
print("Train/Test shapes:", Xtr.shape, Xte.shape) # (60000, 28, 28) / (10000, 28, 28)
# 拉平成向量以供 KNN 使用
Xtr_rows = Xtr.reshape(Xtr.shape[0], -1)[:1000] # (60000, 784)
Ytr = Ytr[:1000]
Xte_rows = Xte.reshape(Xte.shape[0], -1)[:50] # (10000, 784)
Yte = Yte[:50]
# 选取验证集最优 k
# 找出验证集里哪个 k 的准确率最高
best_k = 1
# 用最优 k 在测试集评估(可与更大的训练集组合)
# 这里将训练集扩大为全部 60000,用于最终测试评估(可能较慢,酌情改为部分)
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
Yte_pred = nn.predict(Xte_rows, k=best_k)
test_acc = np.mean(Yte_pred == Yte)
print(f'test acc (k={best_k}): {test_acc*100:.2f}')可视化效果
import os
import numpy as np
import matplotlib.pyplot as plt
from class_all.class2 import NearestNeighbor # 需为支持 k 的版本
from class_all.class1 import load_mnist
# ---------- 主流程 ----------
# 加载 MNIST 数据集(若本地无数据,可把 download=True 以自动下载)
Xtr, Ytr, Xte, Yte = load_mnist(download=False)
print("Train/Test shapes:", Xtr.shape, Xte.shape) # (60000, 28, 28) / (10000, 28, 28)
# 将图像由 28x28 拉平成 784 维向量,便于最近邻分类器进行欧氏距离计算
# 这里为了运行速度,只取前 1000 个训练样本,以及前 50 个测试样本
Xtr_rows = Xtr.reshape(Xtr.shape[0], -1)[:1000]
Ytr = Ytr[:1000]
Xte_rows = Xte.reshape(Xte.shape[0], -1)[:50]
Yte = Yte[:50]
# 设定 k 值,这里固定为 1(即最近邻法)
best_k = 1
# 训练并评估:将训练特征与标签“喂给”最近邻分类器,然后在测试集做预测并计算准确率
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
Yte_pred = nn.predict(Xte_rows, k=best_k)
test_acc = np.mean(Yte_pred == Yte)
print(f'test acc (k={best_k}): {test_acc*100:.2f}')
# ---------- 仅可视化“最后 50 个样本”的预测结果与其对应的 Top-1 训练邻居 ----------
import numpy as np
import matplotlib.pyplot as plt
# 指定需要展示的样本数量(这里为 50)
# 若当前测试子集本身少于 50,则按实际数量展示
n = 50
# 为了避免与上游裁剪不一致,这里直接基于当前子集取前 n 个(等价于“最后 50”在你当前的切片配置下)
# 三者切片必须一致:测试特征向量、测试标签、以及用于显示的测试图像
Xte_last_rows = Xte_rows
imgs_last = Xte_rows.reshape(n, 28, 28) # 将向量还原为 28x28 便于显示
Yte_last = Yte
Yte_pred_last = Yte_pred
# 逐个计算每个测试样本与全部训练样本之间的欧氏距离,找到距离最小的那个训练样本
# 保存其索引、距离值,用于后续展示最近邻图像与标签
nn_indices = np.empty(n, dtype=int)
nn_dists = np.empty(n, dtype=float)
for i in range(n):
x = Xte_last_rows[i:i+1] # 取第 i 个测试样本(形状:(1, 784))
dists = np.linalg.norm(Xtr_rows - x, axis=1) # 计算与所有训练样本的欧氏距离(形状:(N_train,))
j = int(np.argmin(dists)) # 最小距离对应的训练样本索引
nn_indices[i] = j
nn_dists[i] = float(dists[j])
# 根据最近邻索引取出对应的训练图像与标签(用于可视化 Top-1 邻居)
nn_imgs = Xtr[nn_indices] # 形状:(n, 28, 28)
nn_labels = Ytr[nn_indices] # 形状:(n,)
# 绘制函数 1:以网格形式展示测试图像,并在标题标注预测值/真实值
# 绿色表示预测正确,红色表示预测错误
def show_test_grid(images, y_true, y_pred, rows=5, cols=10, title="Last-N test samples (green=correct, red=wrong)"):
n_show = min(len(images), rows*cols) # 防止超出网格容量
plt.figure(figsize=(cols*1.6, rows*1.6))
for i in range(n_show):
ax = plt.subplot(rows, cols, i+1)
ax.imshow(images[i], cmap='gray') # 使用灰度显示手写数字图像
ax.axis('off') # 关闭坐标轴
ok = (y_pred[i] == y_true[i]) # 判断是否预测正确
ax.set_title(
f"P:{int(y_pred[i])} / T:{int(y_true[i])}",
fontsize=9,
color=('green' if ok else 'red') # 正确为绿,错误为红
)
plt.suptitle(title, fontsize=14, y=1.02)
plt.tight_layout()
plt.show()
# 绘制函数 2:以网格形式展示与每个测试样本对应的“最相似训练图像(Top-1 邻居)”
# 标题中附带该邻居的标签与到测试样本的欧氏距离,便于理解判别依据
def show_neighbor_grid(images, labels, dists, rows=5, cols=10, title="Top-1 training neighbor per test sample"):
n_show = min(len(images), rows*cols)
plt.figure(figsize=(cols*1.6, rows*1.6))
for i in range(n_show):
ax = plt.subplot(rows, cols, i+1)
ax.imshow(images[i], cmap='gray')
ax.axis('off')
ax.set_title(f"NN:{int(labels[i])} / D:{dists[i]:.1f}", fontsize=9)
plt.suptitle(title, fontsize=14, y=1.02)
plt.tight_layout()
plt.show()
# 依次绘制:
# 1) 测试样本网格(展示预测值与真实值)
# 2) 对应的 Top-1 训练邻居网格(展示邻居标签与距离)
show_test_grid(imgs_last, Yte_last, Yte_pred_last, rows=5, cols=10)
show_neighbor_grid(nn_imgs, nn_labels, nn_dists, rows=5, cols=10)深度学习代码介绍
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 1. 数据准备 (包含下载、预处理与加载)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
data_path = r'C:\code\ccs2\check\data'
# 根目录建议改为你习惯的路径,例如 './data'
train_set = datasets.MNIST(root=data_path, train=True, download=True, transform=transform)
test_set = datasets.MNIST(root=data_path, train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)
test_loader = DataLoader(test_set, batch_size=1000, shuffle=False)
# 2. 定义精炼的 CNN 模型
class TinyCNN(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(1, 16, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(16, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(32 * 7 * 7, 128), nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x): return self.net(x)
# 3. 训练与测试逻辑
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TinyCNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
print(f"Using device: {device}")
# 训练 1 轮即可达到约 98% 准确率
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
criterion(model(data), target).backward()
optimizer.step()
# 建议后缀使用 .pth 或 .pt
torch.save(model.state_dict(), "mnist_model.pth")
print("模型权重已成功保存至 mnist_model.pth")
# 4. 测试准确率
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
correct += (output.argmax(1) == target).sum().item()
print(f"\nFinal Test Accuracy: {100. * correct / len(test_loader.dataset):.2f}%")深度学习预测代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
class TinyCNN(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(1, 16, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(16, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(32 * 7 * 7, 128), nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x): return self.net(x)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def predict_single_image(image_path):
# 1. 实例化模型并加载权重
model = TinyCNN().to(device)
model.load_state_dict(torch.load("mnist_model.pth"))
model.eval() # 必须切换到评估模式
# 2. 图像预处理 (必须与训练时的处理完全一致)
from PIL import Image
# 读取图片 -> 转为灰度 -> 缩放到 28x28
img = Image.open(image_path).convert('L').resize((28, 28))
# 转换逻辑:PIL -> Tensor -> 归一化 -> 增加 Batch 维度 (1, 1, 28, 28)
img_tensor = transform(img).unsqueeze(0).to(device)
# 3. 执行预测
with torch.no_grad():
output = model(img_tensor)
prediction = output.argmax(dim=1).item()
print(f"这张图片的识别结果是: {prediction}")
return prediction
predict_single_image(r'D:\Code\class_all\mnist_sample.png')